
Das Thema Index-Diät ist aktuell in aller Munde. Und das ist nicht verwunderlich – denn durch den Content-Hype wurden so viele Inhalte erstellt, dass irgendwann eine Übersättigung eintreten musste. Es wurde (und wird immer noch) einfach so viel Content veröffentlicht, dass gar nicht alles einen Mehrwert für BesucherInnen oder Suchmaschinen bieten kann.
Du bist mehr der visuelle Typ?
Weiter unten findest du eine Infografik, die dir diesen Artikel übersichtlich zusammenfasst!
Was ist die Ausgangssituation?
Beim Thema Content ist es wie bei allen anderen Hypes auch. Was als sinnvolle Neuerung startet, wird dadurch, dass immer mehr Menschen auf den Zug aufspringen und auch ein Stück vom Kuchen abhaben wollen, ad absurdum geführt. Und so wurde Content vom King zum Allheilmittel – und die Qualität blieb dabei oft auf der Strecke. Auch das Kalkül, mithilfe dieser Inhalte für alle möglichen und unmöglichen Suchbegriffe und Kombinationen gefunden zu werden, ging nur in wenigen Fällen wirklich auf.
Besonders, seit Google mit Panda und Co. auch ein Augenmerk auf die inhaltliche Qualität des Contents hat, ist dieses Vorgehen nun wirklich nicht mehr zu empfehlen. Oft führt eine solche Nutzung von Inhalten einfach zu einem langsamen Tod in den Suchergebnissen. Die „viel hilft viel“-Seiten, die zu allem etwas zu sagen haben, sind hier ein gutes Beispiel:
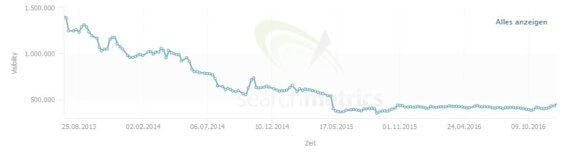
Slow Death einer Seite mit massiven Problemen im Hinblick auf Thin Content und Near Duplicate Content
Doch was kannst du tun, um dafür zu sorgen, dass all die nutzlosen Inhalte – von Duplicate Content bis hin zu den Textbroker 2-Sterne-Texten – deinen Erfolg in den SERPs nicht gefährden? Zuallererst solltest du sicherstellen, dass nur die Seiten in den Index kommen, die auch wirklich für die Suche wichtig sind. Doch welche wären das?
Bei Online-Shops sind die für die Suche relevanten Seiten die Startseite, die Kategorieseiten, die Sub-Kategorieseiten, die Produktseiten und ggf. auch die Themenseiten. Bei Publisher-Seiten sind die Startseite, die Themenkategorien, die Sub-Kategorien, die Artikel, die Medien-Inhalte (wie Videos oder Podcasts) und die langen Inhalte (wie PDFs und Whitepaper) wirklich wichtig.
Im Gegensatz dazu sind folgende Seiten in den meisten Fällen nicht für die Suche relevant:
Sicher kennst auch du viele Websites, die Suchergebnisseiten oder Duplikate in den Index schieben. Das zeigt, warum das Thema Index-Diät immer relevanter wird – und diese Entwicklung spiegelt sich auch in den Programmen der einschlägigen Konferenzen wider.
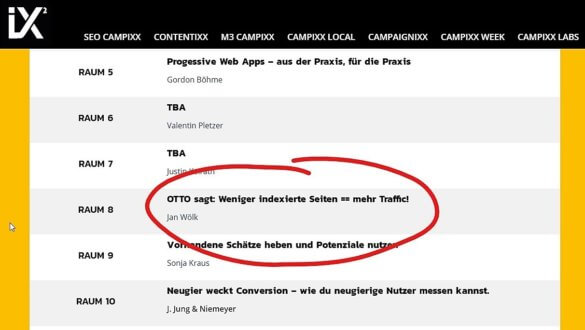
Angekündigter Vortrag aus dem Hause OTTO zur SEO CAMPIXX 2018
Wann solltest du eine Index-Diät ansetzen?
Grundsätzlich gibt es zwei Kernprobleme, die sich aus einer Masse an schlechten Inhalten ergeben:Google (und jede andere Suchmaschine auch) muss alle vorhandenen Dokumente crawlen, um sie zu indexierenGoogle (und jede andere Suchmaschine auch) muss die indexierten Dokumente auf ihre Relevanz hin analysieren, um sie in der Suche ausspielen zu können
Wenn du also viele „wertlose“ Inhalte anbietest, verschwendest du wichtige Ressourcen. Im Endeffekt lenkst du die Crawler damit von deinen wirklich guten Inhalten ab. Diese werden dann vielleicht nicht schnell genug gecrawlt und indexiert. Außerdem kann es passieren, dass die Masse an schlechten Inhalten die Relevanz deiner guten Inhalte im Index verwässert.
Dazu ein Beispiel:
Du bietest einen Artikel zum Thema „Indexbereinigung“ an. Dieser soll entsprechend zum Keyword „indexbereinigung“ ranken. Der Artikel wird über verschiedene Themenseiten verlinkt und dadurch über parametisierte URLs erreichbar:
Die Frage ist nun: Welches dieser fünf Dokumente ist das korrekte und wichtige? Denn faktisch hast du fünf Artikel mit identischen Inhalten. Wenn Google sich nun nicht für eine Version entscheiden kann, wird sich die Maschine einen anderen Inhalt aussuchen. Da wäre es doch deutlich besser, wenn du ein wirklich starkes Dokument hättest.
Wie kannst du „Überschuss“ identifizieren?
Wie kannst du es also schaffen, die überschüssigen Seiten zu identifizieren? Nun, hier solltest du am besten in mehreren Schritten vorgehen.
1. Schritt: Die Site-Abfrage
Für einen ersten Überblick kannst du eine Site-Abfrage in Google durchführen. Entweder mit „site:Domain“ oder mit „site:Thema“. Doch Achtung: Die Site-Abfrage ist nur eine Schätzung und liefert keinen hundertprozentig zuverlässigen Einblick in die tatsächliche Anzahl der indexierten Seiten.
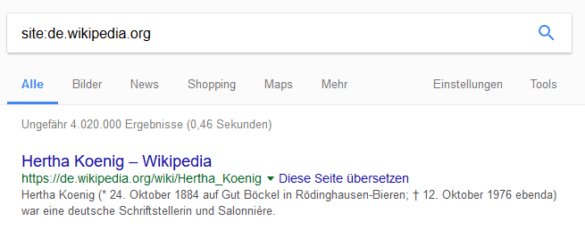
Die Site-Abfrage der deutschen Wikipedia bringt etwa 4 Millionen indexierte Dokumente zum Vorschein
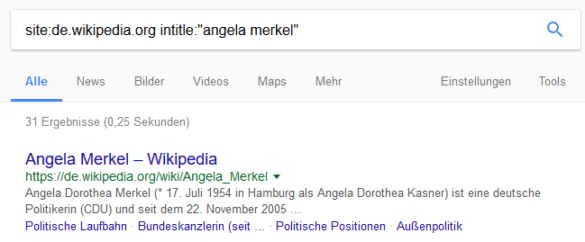
Die Site-Abfrage der deutschen Wikipedia nach „Angela Merkel“ gibt etwa 31 indexierte Dokumente zurück
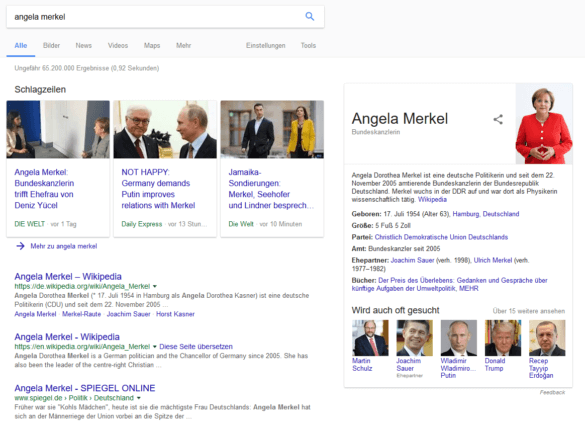
In der Google-Suche nach „Angela Merkel“ rankt Wikipedia wirklich super
Dieses Beispiel ist natürlich erst einmal etwas konstruiert, da Wikipedia nicht nur wegen der Art der Indexierung gut rankt. Die Seite hat unter anderem auch einen hohen Trust-Bonus. Näher an der Wirklichkeit wäre da folgendes Beispiel.

Conrad.de hat circa 421.000 Dokumente im Index
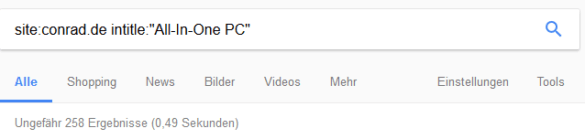
Davon behandeln, sofern alle Titel gut gepflegt sind, ca. 258 das Thema „All-in-One PC“ – dabei sind es Produktseiten, die gut für die Marke-Typ-Kombination ranken können
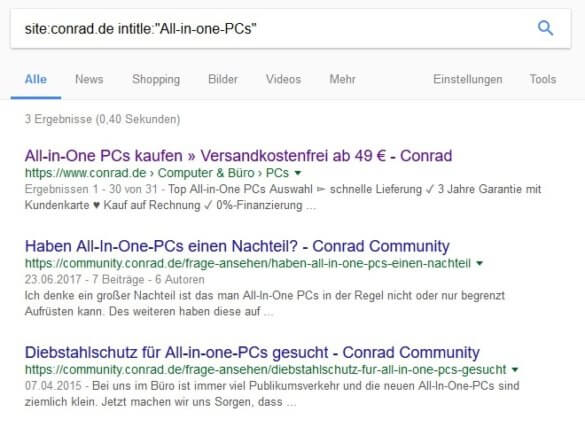
Drei Dokumente verwenden den Plural – dabei handelt es sich unter anderem um eine Kategorieseite, die sich hervorragend für das Ranking auf generelle Abfragen eignet
2. Schritt: Der genaue Blick auf die Performance
Hierbei musst du vor allem deine Sichtbarkeit analysieren. Und zwar nicht nur die der gesamten Domain, sondern auch auf Verzeichnis-Ebene. Analysiere also die indexierten URLs auf dieser Ebene und gleiche sie mit den rankenden URLs ab. Schaue dir zudem die Traffic-Daten an, um zu erkennen, welche Seiten überhaupt regelmäßig besucht werden.
3. Schritt: Klassische „Opfer“ identifizieren
Hier wird es Zeit, tiefer in deine Website einzusteigen. Lasse einen Crawl über die Seite laufen und mache dich mit SEO-Tools auf die Suche nach folgenden Indikatoren, die auf Ausschussware hinweisen:
4. Schritt: Die Logfile-Analyse
Umgang mit Überschuss
Hast du nun die Seiten identifiziert, die du aus dem Index entfernen möchtest, so stellt sich natürlich die Frage, wie du das anstellen kannst. Zunächst solltest du nicht kopflos das Noindex-Tag anwenden. Denn dies beseitigt nur das Symptom, nicht aber das eigentliche Problem.
Inhalte konsolidieren
Das Konsolidieren von Inhalten ist die klassische Methode für Publisher und Magazine. Dabei identifizierst du durch internes Tagging sowie die Analyse von Titles und Überschriften ähnliche und sehr ähnliche Inhalte und führst sie zusammen – zum Beispiel auf einer Übersichtsseite. Im Bestfall nutzt du die Gelegenheit und überarbeitest die Inhalte direkt noch einmal.
Wie du das genau anstellen kannst, verdeutlicht das folgende Beispiel:
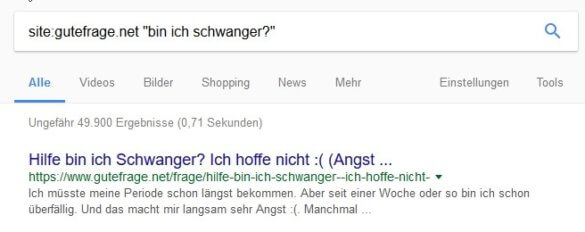
Gutefrage.net bietet zum Thema „Bin ich schwanger“ knapp 50.000 Dokumente an
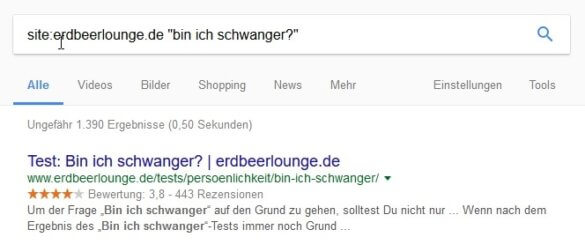
Zum gleichen Thema gibt es bei Erdbeerlounge.de lediglich etwa 1390 Ergebnisse
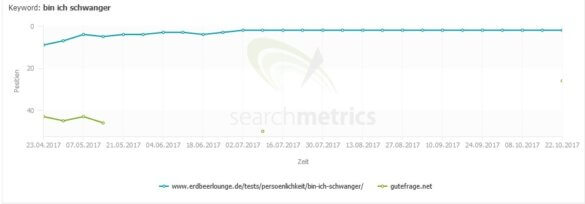
Im Vergleich rankt Erdbeerlounge daher deutlich stabiler
Wenn du deine Inhalte konsolidierst, darfst du allerdings nie die vier zentralen SEO-Punkte vergessen:
Manchmal wird es dich jedoch nicht weiterbringen, deine Inhalte zu konsolidieren. Und zwar dann, wenn du viele 1:1 Duplikate auf deiner Seite hast. Dann (und nur dann) lohnt es sich, die Inhalte zu kanonisieren. Das gilt besonders bei der Indexierung von Inhaltsalternativen wie Print-Versionen, Mobilversionen oder PDFs.
Das würde dann folgendermaßen aussehen:
Wir haben
1. https://www.beispielseite.de/original-dokument
2. https://www.beispielseite.de/original-dokument-print-version
3. https://www.beispielseite.de/original-dokument-kurzversion
4. https://mobil.beispielseite.de/original-dokument-mobilversion
Kanonisierung im Quelltext von HTML Dokumenten:
Wir haben:
1. https://www.beispielseite.de/original-dokument
2. https://www.beispielseite.de/original-dokument-pdf-version.pdf
Kanonisierung über Header:
HTTP/1.1 200 OK
Date: Thu, 26 Oct 2017 10:44:59 GMT
Link: <https://www.beispielseite.de/original-dokument>; rel=”canonical”
X-SP-TE: 6151
X-Robots-Tag: index, follow, noarchive, noodp
Content-Type: text/html;charset=UTF-8
(Beispiel-Header)
Inhalte von Crawling & Indexierung ausschließen
Um die gewünschten Inhalte einfach nur vom Crawling und Indexing auszuschließen, kannst du mit der robots.txt arbeiten:
<meta name=”robots” content=”noindex, follow”>
Das behebt aber leider nicht das grundsätzliche Problem. Viel besser ist es, eine facettierte Suche mit PRG Pattern einzusetzen. So vermeidest du, dass Crawler die aufgerufenen URLs „sehen“ und crawlen können. Der Crawler bekommt dann lediglich die „Originalseite“ ausgespielt – und die Nutzer sowie Nutzerinnen merken von alledem Beim PRG Pattern musst du jedoch beachten, dass es lösungsabhängig ist, ob Tabbed Browsing unterstützt wird. Außerdem musst du die SEO-relevanten Filtervarianten vom PRG ausnehmen. Dabei handelt es sich zum Beispiel um Produkt-Farbe-Kombinationen mit hohem Suchvolumen.
Radikalkur: Inhalte deindexieren
In vielen Fällen helfen jedoch all diese Möglichkeiten auch nicht wirklich weiter. Wenn du zum Beispiel nicht relevante Inhalte aus grauer Vorzeit im Index hast, bringt es dir nichts, diese zu kanonisieren oder zu konsolidieren. Denn welchen Zweck sollen veraltete Produktrezensionen, Profilseiten, Produktseiten, Markenseiten, Themenseiten oder Autorenseiten noch erfüllen?
Mache daher den internen Test und stelle dir drei Fragen:
1. Ranken die Seiten (noch)?
2. Haben sie internen und externen Traffic?
3. Werden sie über die interne Suche gesucht und gefunden?
Solltest du hier drei Mal mit nein antworten, so hilft nur noch der Statuscode 410. Um dieses Löschen zu beschleunigen, kannst du die entsprechenden URLs in eine externe Sitemap packen. Beobachte diese dann, bis sie komplett von Google verarbeitet wurde und lösche sie danach wieder. Der letzte Punkt ist nicht zu unterschätzen, denn wenn du das Löschen vergisst, wird es viele Fehler in der Search Console hageln. 410 gehören nämlich grundsätzlich nicht in die Sitemap.
Und dann?
Nun hast du einen Fahrplan, mit dem du deine ungeliebten Inhalte verbessern oder loswerden kannst. Doch die Index-Diät ist kein Selbstzweck! Das Ganze bringt dir nur wenig, wenn du nicht vorher belastbare Ziele definierst. Dazu gehören:
Um sicherzustellen, dass diese Ziele auch erreicht werden, solltest du natürlich im Nachgang die Log-Files überwachen und auf Veränderungen hin prüfen. Zudem solltest du auch die Rankings der neuen bzw. übrigen Seiten im Blick haben und den Traffic auf den betroffenen URLs beobachten. Und zur Sicherheit kann es auch nicht schaden, in regelmäßigen Abständen die Weiterleitungen zu überprüfen.
Dann kannst du es schaffen, dass deine Sichtbarkeit ebenso ansteigt, wie die in den folgenden Beispielen. Die Marker zeigen dabei das Datum an, an denen die überschüssigen URLs abgebaut wurden. Die Vergleichswerte in den Tabellen sprechen eine deutliche Sprache. Viel Spaß beim Nachmachen.
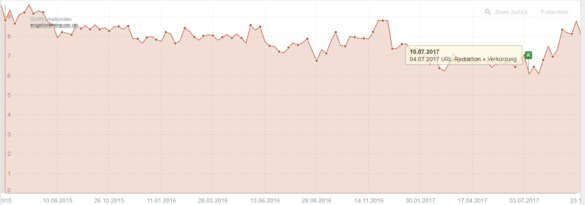
18.000 indexierte Seiten statt mehr als 380.000 – und der Erfolg stellt sich ein
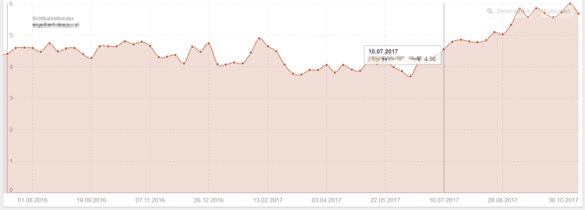
10.000 anstatt 200.000 indexierte Seiten führen zu einem spürbaren Anstieg der Sichtbarkeit




